【计算机视觉】评估语义分割精确度的指标
假设共有$k+1$个类(从$L_0$到$L_k$,其中包含一个空类或背景),$p_{ij}$表示本属于类$i$但被预测为类$j$的像素数量。即,$p_{ii}$表示真正的数量,而$p_{ij}$ $p_{jj}$则分别被解释为假正和假负,尽管两者都是假正与假负之和。
像素精度(Pixel Accuracy, PA)
像素精度指的是正确标记的像素占总像素的比例。
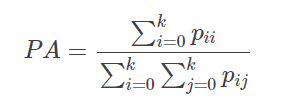
均像素精度(Mean Pixel Accuracy,MPA)
MPA是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。
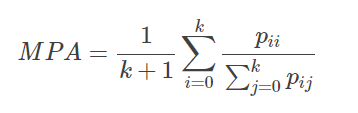
当一张图中目标占一小部分,背景占据大部分像素,即使模型不能正确分割出目标,指标像素精度也会接近于1,即模型分割精确度较高。这类问题叫做类别不平衡(class imbalance)。然而在许多数据集中都存在类别不平衡的现象,所以像素精度不是常用指标。
均交并比(Mean Intersection over Union, MIoU)
MIoU为语义分割的标准度量。其计算两个集合的交集和并集之比,在语义分割的问题中,这两个集合为真实值(ground truth)和预测值(predicted segmentation)。这个比例可以变形为真正数(Intersection)比上真正、假负、假正(Union)之和。在每个类上计算IoU,之后平均。
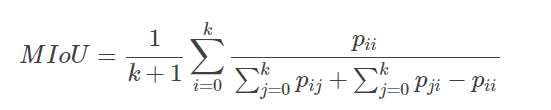
MIoU直观理解
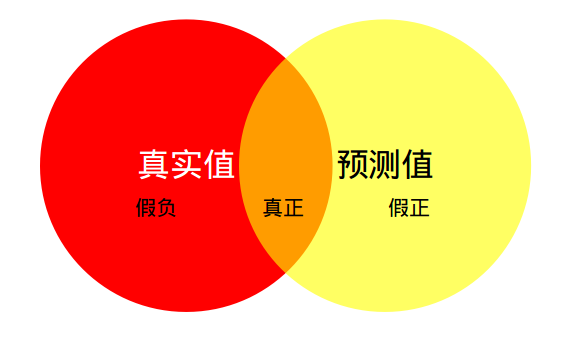
如下图所示,红色圆代表真实值,黄色圆代表预测值。橙色部分红色圆与黄色圆的交集,即真正(预测为1,真实值为1)的部分,红色部分表示假负(预测为0,真实为1)的部分,黄色表示假正(预测为1,真实为0)的部分,两个圆之外的白色区域表示真负(预测为0,真实值为0)的部分。 MIoU计算的是计算A与B的交集(橙色部分)与A与B的并集(红色+橙色+黄色)之间的比例,在理想状态下A与B重合,两者比例为1 。
code
def iou_coef(y_true, y_pred, smooth=1):
intersection = sum(y_pred & y_true)
union = sum(y_true) + sum(y_pred) - intersection
iou = (intersection + smooth) / (union + smooth)
return iou
上述代码计算一个类别的真实分割与预测分割的交并比,y_true、y_pred都是numpy.array。但是上面代码运行较慢,可参考下面代码提升运算速度(摘自github,原代码可快速计算多个类别的交并比)。
import numpy as np
def fast_hist(a, b):
k = (a > 0) & (a <= 1 )
hist = np.bincount(a[k].astype(int) + b[k], minlength=1)
iou = hist[2] / (hist[1] + hist[2])
return iou
Dice Coefficient (F1 Score)
Dice系数指的是2*真实值与预测值的交集除以真实值与预测值的总和。Dice系数与IoU非常相似。 它们是正相关的。和IoU一样,Dice的范围都在0到1之间,其中1表示预测值与真值之间的最大相似性。
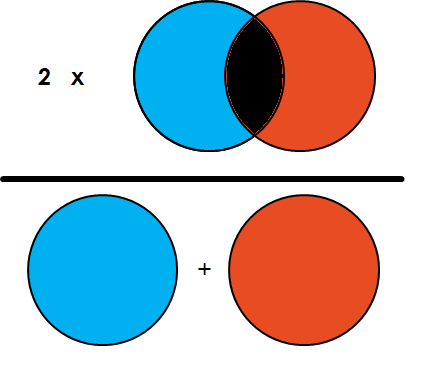
code
from keras import backend as K
def dice_coef(y_true, y_pred, smooth=1):
intersection = K.sum(y_true * y_pred, axis=[1,2,3])
union = K.sum(y_true, axis=[1,2,3]) + K.sum(y_pred, axis=[1,2,3])
dice = K.mean((2. * intersection + smooth)/(union + smooth), axis=0)
return dice
references