#【深度学习】Feature-wise transformations
@(2019-2020年度论文阅读)[超分辨率]
A simple and surprisingly effective family of conditioning mechanisms.
许多现实世界中的问题需要集成多源信息,有时候这些问题包含multiple,distinct modalities of information,比如vision,language,audio等,在场景理解或者看图回答问题时需要。或者有时候这些问题包含相同类型输入的多个源,也就是当总结一些文档或者以另外一种风格绘制一张图像时。
 处理这类型问题时,在另外一个源的信息上下文中处理一个源的信息是有意义的。举例来说,上图右边这个例子,在问题的上下文中可以从图像中抽取meaning。在机器学习中,我们经常指
处理这类型问题时,在另外一个源的信息上下文中处理一个源的信息是有意义的。举例来说,上图右边这个例子,在问题的上下文中可以从图像中抽取meaning。在机器学习中,我们经常指代这种context-based处理为conditioning:一个模型所承载的运算被一个辅助输入所抽取的信息conditioned或者modulated。the computation carried out by a model is conditioned or modulated by information extracted from an auxiliary input.
找到一个有效的方法来condition on or fuse sources of information是一个开放性的难题,本文聚焦一些特殊类别的方法,我们称之为feature-wise transformations。在许多神经网络中检查了这个方法的使用,用来解决出奇大和多样的问题。所取得成功,我们认为是由于足够灵活在变化的设置中去学习条件输入(conditioning input)的一个高效的表达(effective representation)。在多任务学习的语言中,conditioning signal被认为是一个任务描述,feature-wise transformations学习一个任务表达,允许它们捕获和利用多源信息的关系,即使是在非常不同的问题设置中。
Feature-wise transformations
为了能够引出feature-wise transformations,首先开始一个基础的案例,其中两个输入是图像和类别。为了这个用例的目的,我们对构建一个多种类别的图像生成模型感兴趣。这个模型输入一个类别和一种类型的随机噪声,比如从正态分布中采样的矢量,输出一个请求类别的图像样本。
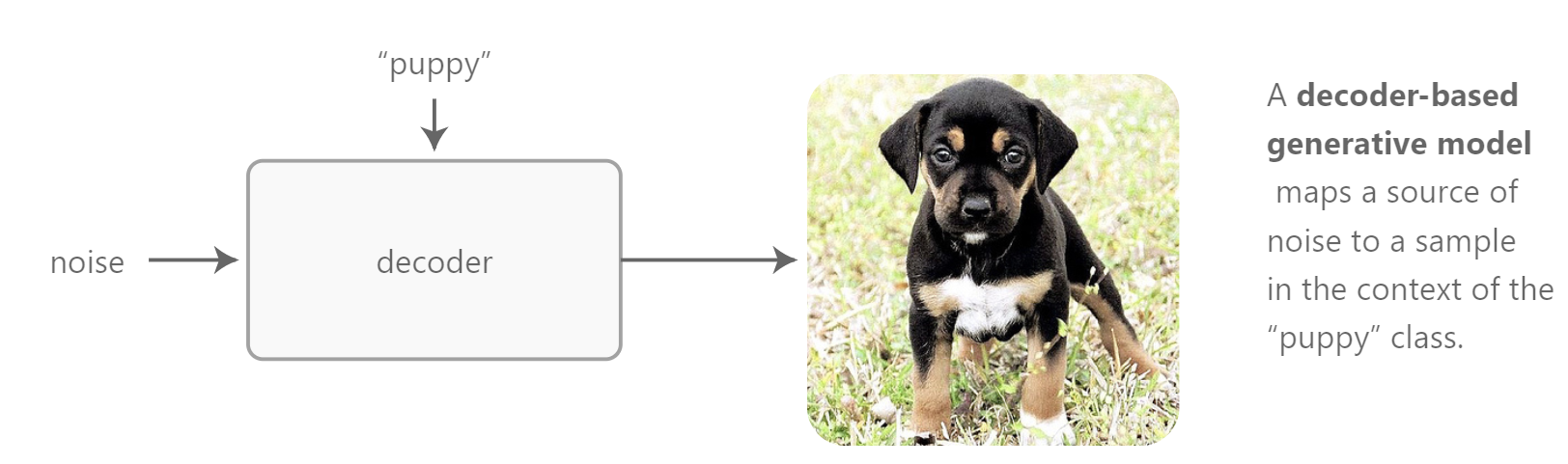
我们第一个直觉可能是去为每一个类别构建一个分立的模型。对于少量类别来讲,这种方法不是一个太糟糕的方案,但是对于成千类别来讲,我们很快会遇到scaling issues,因为要存储和训练的参数数量随着类别数量增长。我们也会失去借助类别之间共性的机会。举例来说,不同类别的狗,puppy,terrier,dalmatian,等具有相同的视觉特征,当从抽象的噪声矢量映射到输出图像时,很可能可以共享计算。
现在想象除了各种类别,我们还需要建模属性,比如size或者color。在这种情况下,我们不能合理地期望为每一个可能的条件组合训练一个分立的网络。
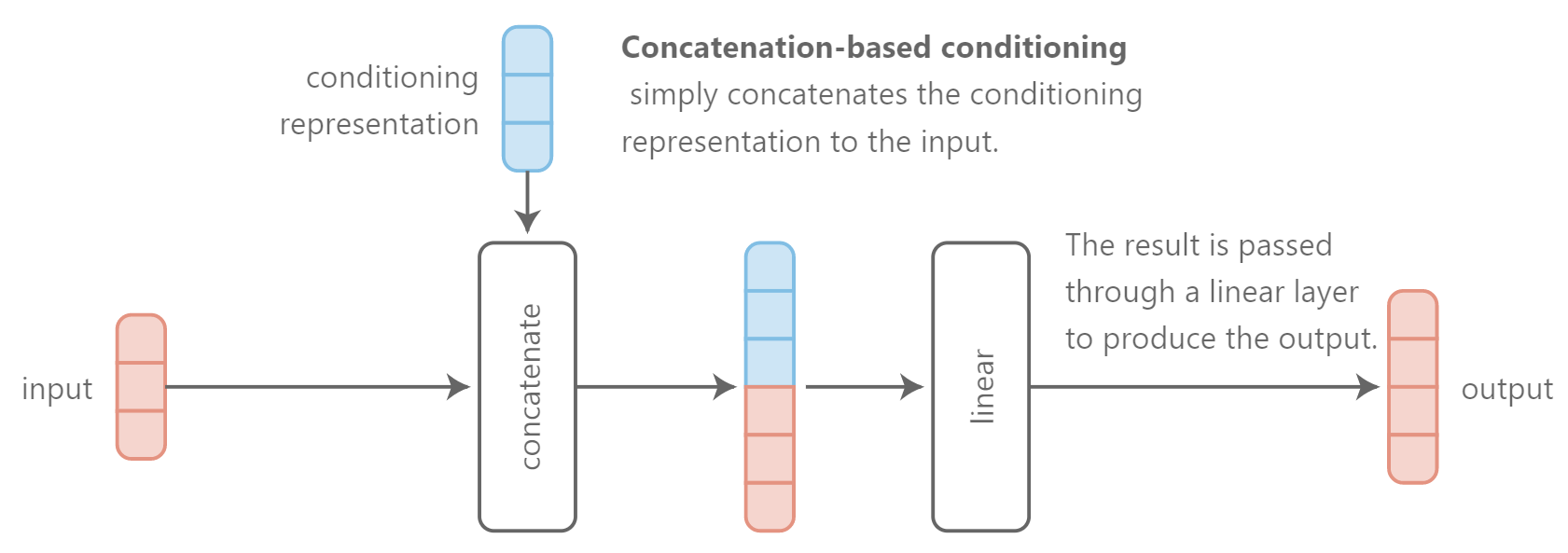
A quick fix(一个权宜之计)是去针对noise vector抽象拼接conditioning information 条件信息的表达representation,并将这个结果作为模型的输入。这个解决方案是quite parameter-efficient,因为我们只需要增加第一层权重矩阵的size。然而,这个方法做出了含蓄的假设:输入是在模型需要使用条件信息的地方。可能这个假设是正确的,或者不是。或者模型直到生成过程的后期才需要插入条件信息(比如,当以纹理为条件时恰好在生成最终像素之前)。In this case,我们需要强迫模型在多个层中携带条件信息而不发生改变。
因为这个操作是cheap的,我们可能也能避免做出任何假设,并针对所有层的输入进行拼接conditioning representations。我们称这种方法是concatenation-based conditioning。
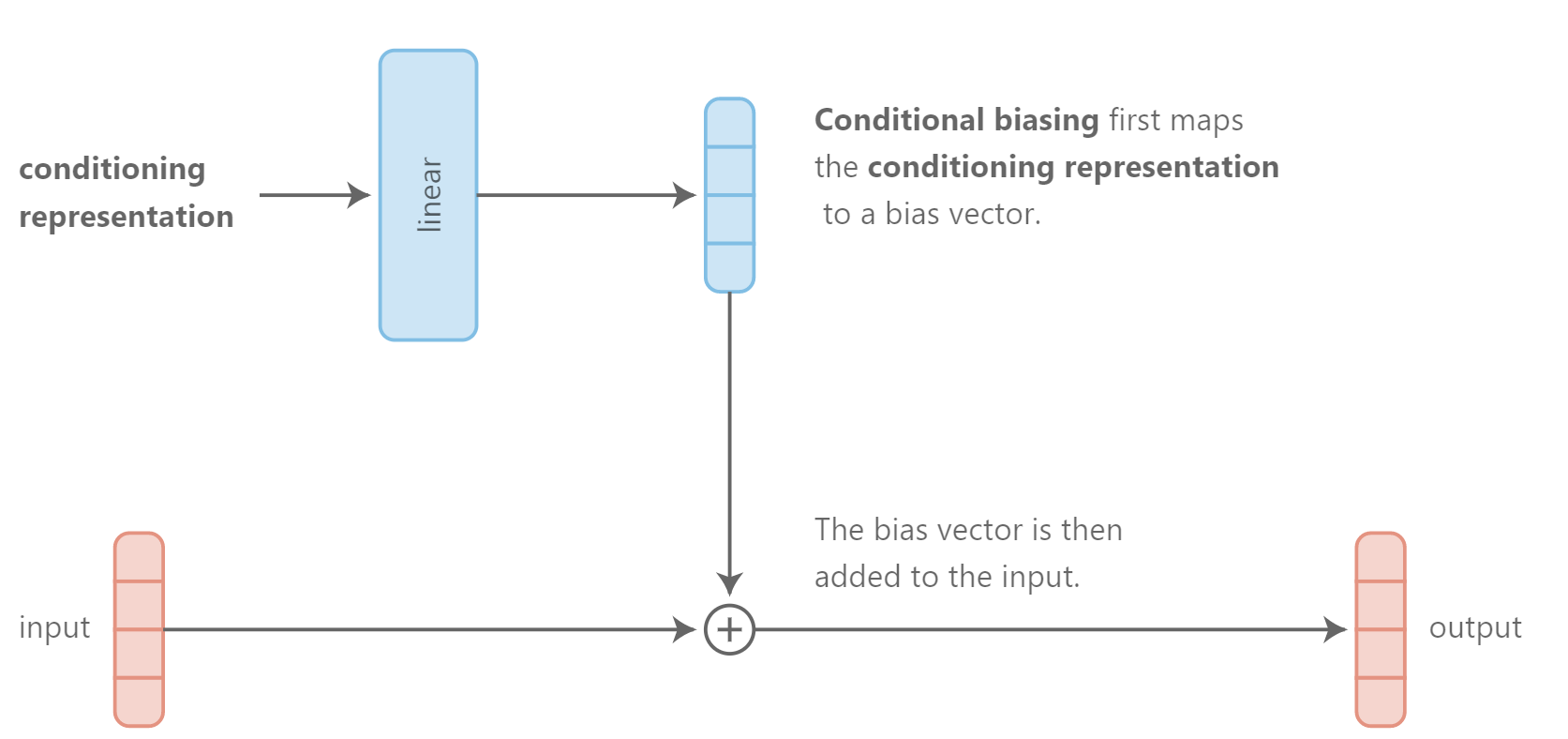
另外一种用于集成条件信息到网络中的高效的方法是通过conditional biasing,也就是基于条件表达增加一个bias到隐层。
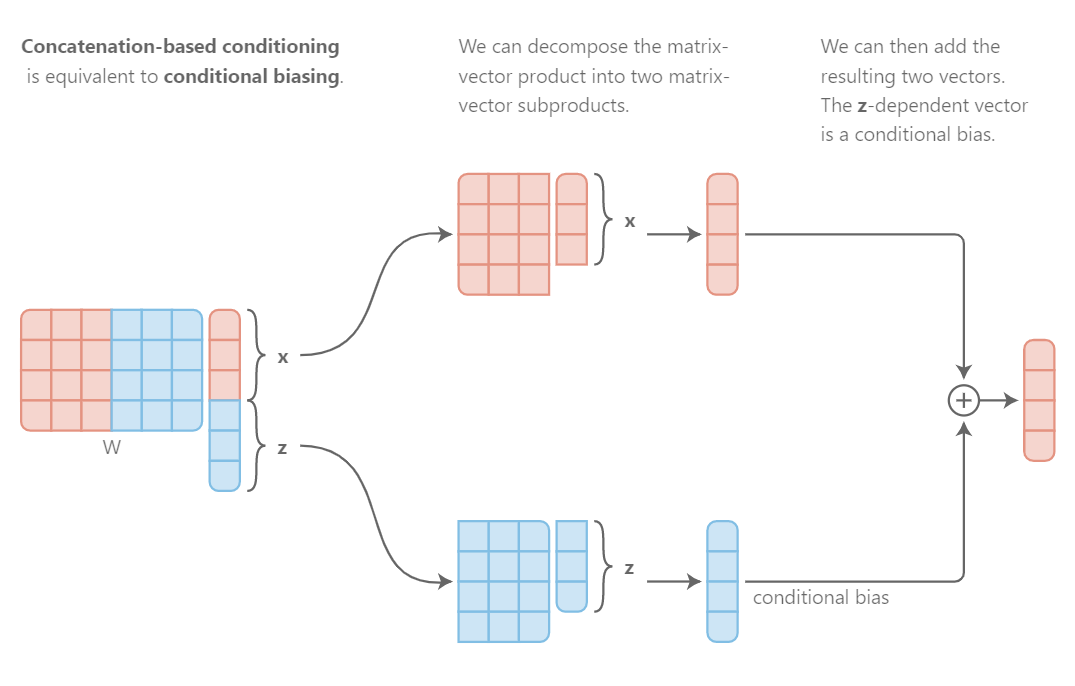
有趣的是,conditional biasing可以看做是另外一种形式的实施concatenation-based conditioning。考虑一个全连接线性层被用于串接输入x和条件表达z。
然而另外一种高效的集成类别信息到网络中的方法是conditional scaling,也就是scaling hidden layers based on conditioning representation。
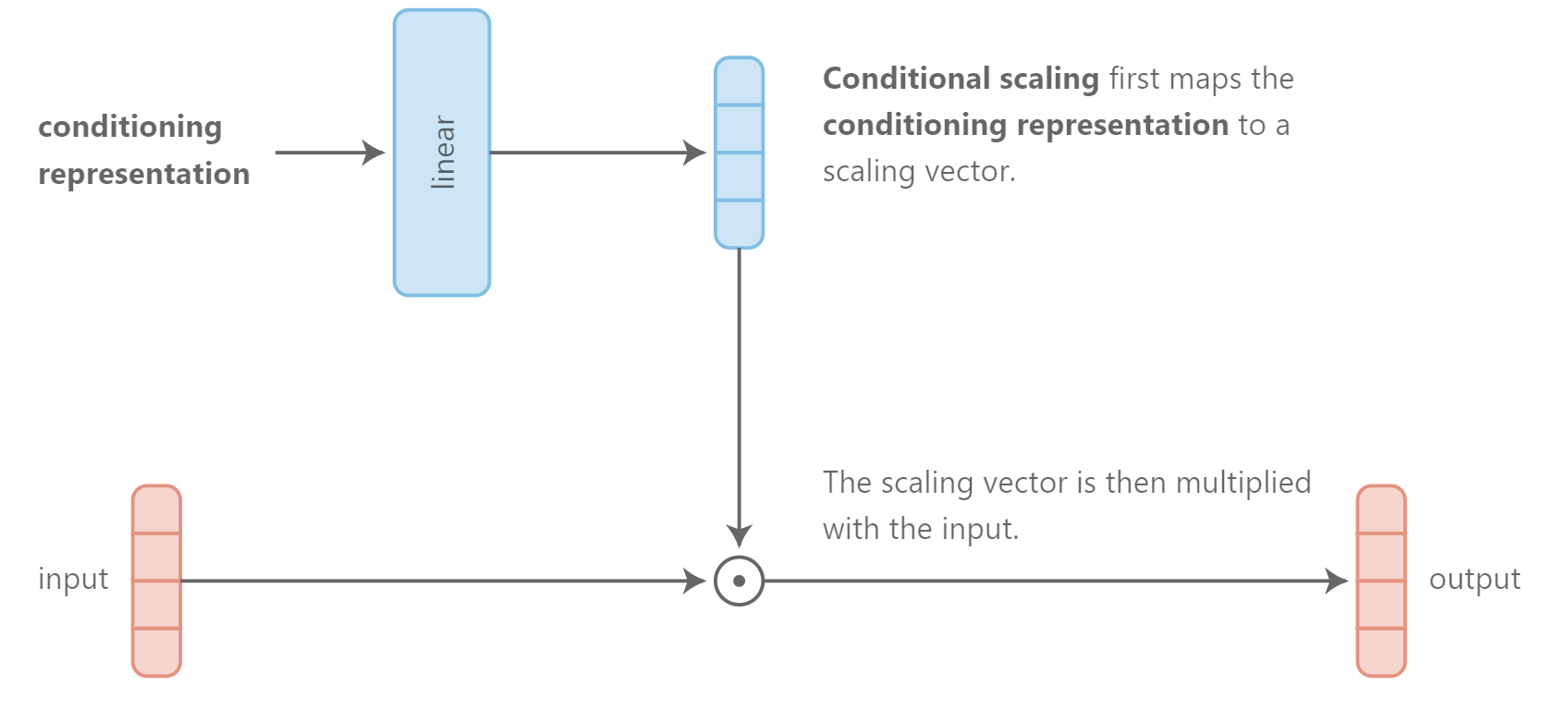
conditional scaling的一个具体示例是feature-wise sigmoidal gating: 我们用一个在0-1之间的值来对feature进行缩放,作为条件表达的一个函数。直观地,这个门允许条件信息选择哪些特征进行前向传递而哪些被置为0去掉。
给定加性的和乘性的相互作用看上去是自然和直觉的,该方法是否可取呢?一个支持乘性交互作用的论据是它在学习输入之间的关系上是有用的,因为这些相互作用能够自然地识别匹配:乘法元素具有相同符号乘法能够产生比乘法元素具有相反符号的结果值更大的结果值。这也是点乘为何经常被用于判定两个矢量的相似度。一个支持加性交互作用的论据是它们在应用中更加自然,对两个输入的联合值较弱的依赖,比如特征融合或者特征检测,也就是判断一个特征是否出现在两个输入中?
本着尽可能对问题做出较少假设的精神,我们可能联合这两个操作到一个conditional affine transformation。
上面所有列出的方法都有一个共性:它们都在特征空间作用,换句话说,它们借助在条件表达和条件化的网络中feature-wise交互作用。也可能使用更加复杂的交互作用,但是feature-wise interactions常常会在有效性和效率之间达成妥协:用于线性预测尺度的scaling和(或者)shifting系数的数量与网络特征数量线性相关。而且,在实践中,它足够在不同设置中建模复杂的现象。
最后,这些transformations only enforce a limited inductive bias and remain domain-agnostic.
术语
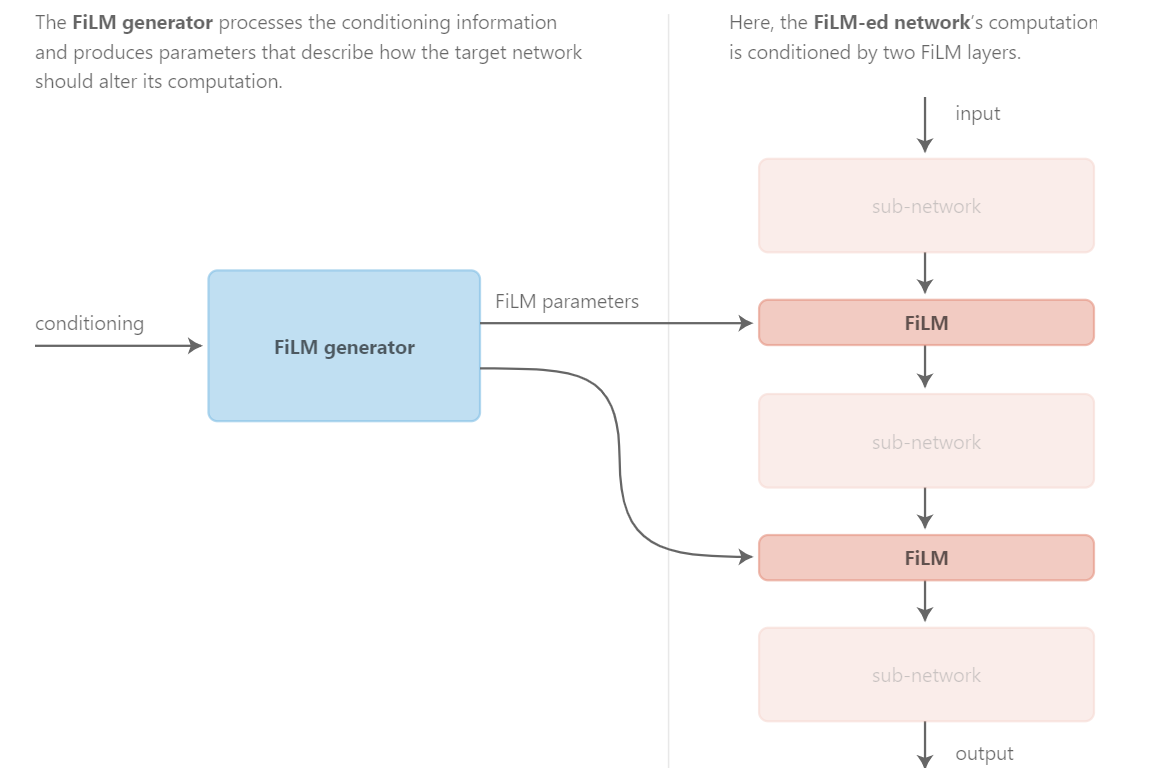 其实那个SFT跟这个基本上没啥差别。
其实那个SFT跟这个基本上没啥差别。

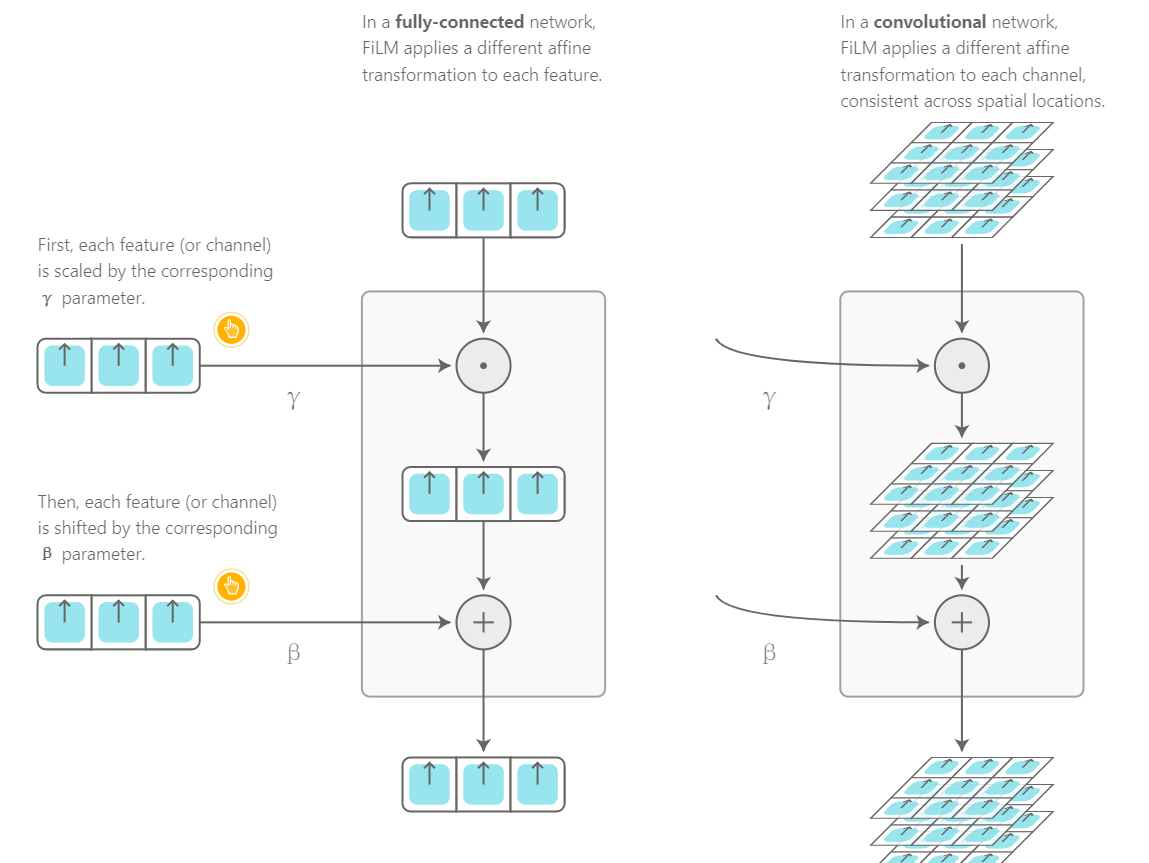
Remarks:其实啊!这些所谓的创新,有很多时候就是借鉴了思路,改装了一下就号称是自己的了。
2020-03-15 张朋艺