【计算机视觉】如何用传统方法在小样本数据集上实现语义分割模型?
问题描述
深度学习虽然很火热,但是数据量不大的时候,深度学习的性能还是比较差的,最主要的是模型能力太强,学出来之后不能泛化,因此一种可选的方法就是 不要处处都是深度模型,试试返璞归真的传统方法。
传统方法
基本上传统机器方法最直观的就是分类、回归,而对于计算机视觉中级任务:语义分割 该如何下手呢?一种最直观的想法就是对像素逐个进行分类。那么对于深度模型,常常是端到端的,采用 CNN 进行 深度特征的提取,那么对于传统方法则需要对一个像素进行特征提取,用于构建这个像素的特征向量,然后再用传统方法中的支撑向量机(SVM)或者随机深林(Random Forest)来对像素的特征矢量进行分类。其实对于深度模型的语义分割网络实际上也是逐个像素点进行的分类。整个解决思路并没有太大的冲突,差别实际上就是 CNN 这种非手工设计的特征,可能具有更强、更抽象或者更富有语义信息。
所以,传统方法解决方案包括三个步骤,一是选择合适的像素特征描述子,二是选择合适的分类器,三是用提取的特征及提供的标签对分类器进行训练。
下面按照这三个步骤逐个进行介绍:
像素特征描述子
Raw Features
对于彩色图像,RGB三个分量可以作为特征矢量的前三个,这是最为简单的特征。只用这些特征进行训练模型很显然不会很 work。所以需要继续耦合其它特征描述子。
Gradient Features
边缘主要发生在像素梯度处,因此通过特定的梯度模板进行梯度计算,然后提取边缘。但是记住了,噪声点也是像素变化或者破坏局部性的一个因素,因此,噪声点的位置也是对应着梯度的位置,因此,进行边缘提取,很重要的一步就是进行噪声的抑制。通常canny算子是一个比较好的边缘提取方法,具体可以参看上一篇笔记中的论述,先进行平滑滤波,然后进行梯度计算,之后进行非极大值抑制,最后再通过双阈值来边缘的提取和生长。

canny 到的边缘信息,可以作为 Raw Features 的一个简易补充。
LBP: local binary pattern
简单来讲就是以该像素点为中心邻域内的每个像素都跟该像素灰度值进行比较,大于为1,小于为0,然后将这作为二进制数几个组合起来得到一个值,即为该像素的局部二值模式值。
在此基础上,还可以有很多变化,比如不同邻域,比如实现旋转不变性的而取LBP二进制值的transform的最小值。这里不做过分深度的探讨,详细可以参考 https://zhangpy.blog.csdn.net/article/details/53872281
灰度共生矩阵:Gray-Level Co-occurance matrix (GLCM)
灰度共生矩阵表现的是图像灰度值在一定方向上、一定距离(相邻间隔)、一定的变化幅度等信息,是一个描述图像二阶联合概率函数的矩阵。
如何理解灰度共生矩阵?首先是方向 $\alpha$,对于一个像素点,一般会定义四个常规方向:0,45,90,135。然后步距 $d$,在多大的范围内进行像素点对儿的判断,比如 $\alpha=0, d=1$,则在该像素点的左右两个像素点进行比较。最后是阶数,这个阶数与图像灰度阶相同,图像有256个灰度级,那么灰度共生矩阵就是 $256\times 256$的矩阵。
如何计算灰度共生矩阵?第一步是将RGB图像转成灰度图,因为纹理特征是结构特征,在不同的R/G/B通道上一般都是一样的,通常直接用亮度图上执行;第二步是将灰度级量化。因为通常256个灰度级太大,计算量会太大,一般会分为8个灰度级或者16个灰度级。以8个灰度级为例,会将原始像素值整除32,再进行像素对儿的灰度判断。所以,存在灰度级压缩的情况,一般会采用直方图拉大灰度级分布范围,防止图像的灰度值分布过于扎堆儿(集中)而导致清晰度过低。第三步是设定用于计算特征值的参数,主要包括滑动窗口的尺寸(5x5或者7x7),步距 d(一般选择d=1,与方向配合上基本上就等于8-邻域)和方向 $\alpha$ (一般取 0,45,90,135)。通常是在求出四个方向矩阵的特征值后求平均值作为最终的特征值共生矩阵。第四步是纹理特征值的计算与纹理特征影像生成。
如何计算纹理特征值呢?首先明白对应关系,给定灰度图像中的一个像素,那么以该像素为中心提取一个矩形窗口,就是上面介绍步骤中的滑动窗口,比如7x7大小。对这个小的7x7的图像块儿进行灰度共生矩阵的计算。然后滑动窗口,步长一个像素,即逐个像素计算,最后能够得到纹理特征影像。
下面以一个具体例子进行来说明,假设已经提取了一个6x6的滑动窗口,灰度被分为4阶,即只包含0,1,2,3四个灰度值:

这里标记坐标原点为(1,1),第三行第二列的坐标为(3,2)。在此基础上,对应计算 $\alpha=0, d=1$ 的共生矩阵,这个共生矩阵大小为 $4\times 4$,那么统计矩阵值(1,2),即在该窗口内灰度值分布是左右为(1,2)或者右左为(1,2)的情况有多少个:
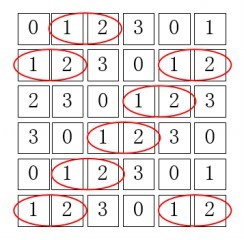
此时共有8个是满足这样灰度值分布情况的,那么对应的灰度共生矩阵的(1,2)位置为8。
对应计算 $\alpha=0, d=1$ 的共生矩阵,这个共生矩阵大小也为 $4\times 4$,那么统计矩阵值(3,0),即在该窗口内灰度值分布是左右为(3,0)或者右左为(3,0)的情况有多少个:
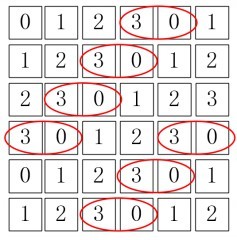
此时共有7个是满足这样灰度值分布情况的,那么对应的灰度共生矩阵的(3,0)为7。
就这样计算出 $\alpha=0, d=1$ 的共生矩阵 逐个位置上的元素,即为:
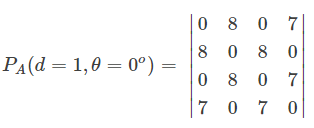
以此类推,计算出$\alpha=45, d=1$,$\alpha=90, d=1$,$\alpha=135, d=1$ 共生矩阵。
下一步要利用这四个矩阵计算GLCM的特征值,首先要归一化对应的灰度共生矩阵:
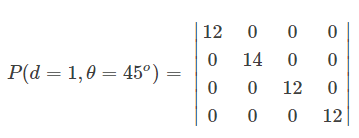
概率化,则矩阵中一个元素P(i,j)则表示按照方向$\alpha$上同时出现灰度值为i和j的概率:

剩下的就是根据这个归一化的灰度共生矩阵,定义各种能够代表一些纹理信息的特征了,包括能量、对比度、相关度和熵等。这个内容放到 Haralick texture features 章节中再进行详细的公式说明。
这样对于一个像素能够得到对应的灰度共生矩阵的特征,这个特征值的维度取决于定义的类别,比如Haralick texture features就在归一化的灰度共生矩阵上定义了9个特征,因而每个像素对应的特征维度为9。随着滑动窗口的不断移动,继续这种计算,最终就能在整幅图上得到每个像素点的特征矢量,单取任意分量就可以构成特征影像图。
Haralick texture features
Haralick texture features就在归一化的灰度共生矩阵上定义了9个特征,纹理特征包括:homogeneity 均一性,gray-tone linear dependencies 灰色调线性依赖关系,contrast 对比度,number and nature of boundaries present 边界的数量和性质,和 complexity of the image 图像复杂度。具体为:
-
Energy:$f_1 = \sum_i\sum_j {p(i,j)}^2$ -
Entropy:$f_2 = -\sum_i \sum_j p(i,j) \log_2(p(i,j)) \ or \ 0 \ if \ p(i,j)=0.$ -
Correlation:$f_3 = \frac{\sum_i \sum_j (i-\mu)(j-\mu) p(i,j)}{\sigma^2}$ -
Inverse difference moment:$f_4 = {\frac{p(i,j)}{1 + (i-j)^2}}$ -
Inertia:$f_5 = \sum_i \sum_j (i-j)^2 p(i,j)$ -
Sum average:$f_6 = \sum {i=2}^{2N_g} i p{x+y}(i)$ -
Cluster shade:$f_7 = \sum_i \sum_j ((i-\mu)+(j-\mu))^3 p(i,j)$ -
Cluster prominence:$f_8 = \sum_i \sum_j ((i-\mu)+(j-\mu))^4 p(i,j)$ -
Haralick's correlation:$f_9 = \frac{\sum_i \sum_j (ij) p(i,j) - \mu_t^2}{\sigma_t^2}$,其中 $\mu_t$ and $\sigma_t$ 是行和或者列和的均值和标准差

传统模型
Support Vector Machine
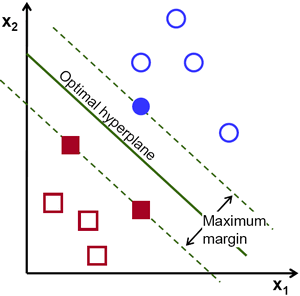
这张图足以说明支撑向量的含义,通过拉格朗日乘子法进行求解,一些原理性的介绍可以参看 https://docs.opencv.org/3.4/d1/d73/tutorial_introduction_to_svm.html
Random Forest
随机深林是由一堆决策树 decision trees 构建的,决策树类似下面的图示:

而随机深林中每个决策树都进行类别预测,因为构建随机深林的决策树尽可能的是不相关的模型,构成一个投票委员会 committee,从而实现互补增强,是属于 Bagging的效果。
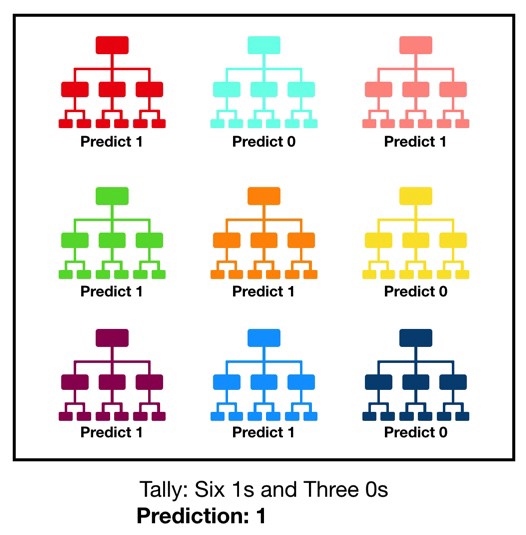
一些原理性的介绍可以参看 https://towardsdatascience.com/understanding-random-forest-58381e0602d2
Gradient Boosting Classifier
Boosting 就是一堆串行的模型集成起来构建鲁棒的模型。与上面介绍的随机森林不同的是,Boosting 采用的是串行过滤的方式。在刚开始做跟踪的时候接触的AdaBoost方法,以及基于Haar-like特征构建朴素贝叶斯分类器的方法,基本上都算是此类。主要是数据经过一个个串行集成的弱分类器,最终比较强的分类器。通常的构成也是决策树,跟随机深林不同的是Gradient Boosting是串行决策,而Random Forest是并行决策,下面的图示可以很好的说明两者的区别:
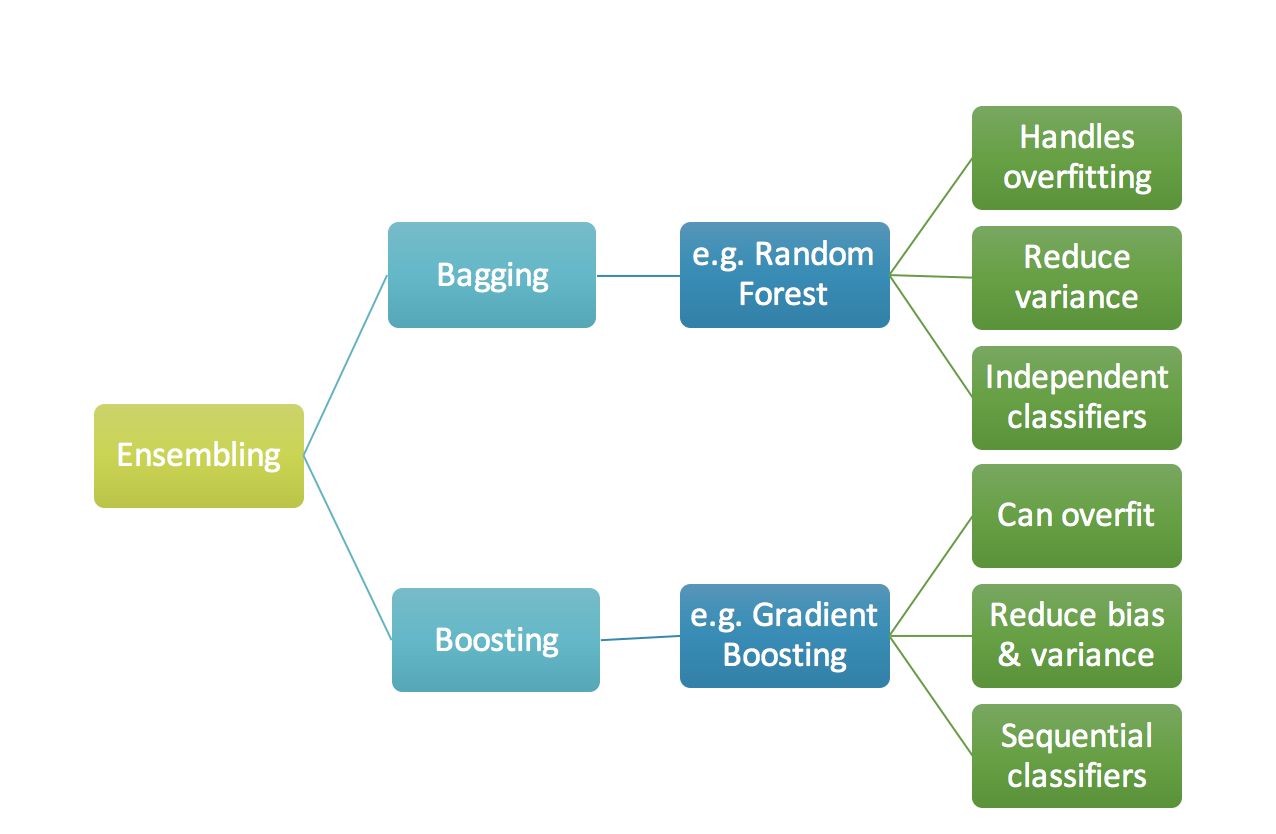
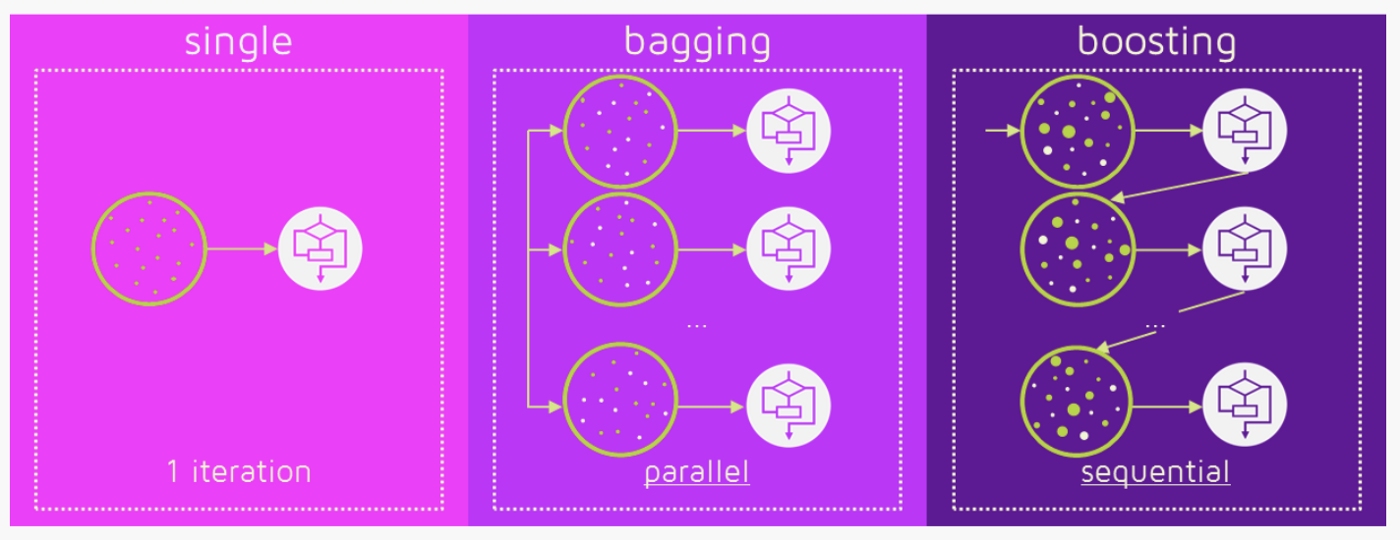
一些细节可以参考:https://medium.com/mlreview/gradient-boosting-from-scratch-1e317ae4587d
基于传统方法进行语义分割例程说明
demo任务描述
原始图像:

分割GT掩摸:

选择合适的像素特征描述子
这里直接选用上面介绍的几种特征构建用于训练分类器的特征,包括[Raw features: R\G\B][LBP texture features: LBP][Haralick texture features: Angular second moment\Contrast\Correlation\Sum of Square: variance\Inverse difference moment\Sum average\Sum variance\Sum entropy\Entropy],共构成13维的特征矢量。
提取 LBP texture features
需要提供灰度图,设置邻域半径lbp_radius以及点数lbp_points:

from skimage import feature
lbp_radius = 24 # local binary pattern neighbourhood
lbp_points = lbp_radius*8
lbp = feature.local_binary_pattern(img, lbp_points, lbp_radius)
提取 Haralick texture features
需要提供灰度图,以及设置窗口大小。这里选择设置计算共生矩阵的distance的默认值为1,上面介绍的四个角度。而对应的ROI即为提取好的图像块儿,也就是滑动窗口抠出来的。最后计算它四个方向上的均值即可。
import mahotas as mt
feature_vec = []
texture_features = mt.features.haralick(roi)
mean_ht = texture_features.mean(axis=0)
[feature_vec.append(i) for i in mean_ht[0:9]]
选择合适的分类器
SVM
from sklearn.svm import SVC
model = SVC()
Random Forest
from sklearn.ensemble import RandomForestClassifier
print ('[INFO] Training Random Forest model.')
model = RandomForestClassifier(n_estimators=250, max_depth=12, random_state=42)
Gradient Boosting Classifier
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0)
用提取的特征及提供的标签对分类器进行训练
首先填入 Raw Features:
feature_img = np.zeros((img.shape[0],img.shape[1],4))
feature_img[:,:,:3] = img
其次填入 LBP texture features:
feature_img[:,:,3] = create_binary_pattern(img_gray, lbp_points, lbp_radius)
最后填入 Haralick texture features:
features = feature_img.reshape(feature_img.shape[0]*feature_img.shape[1], feature_img.shape[2])
h_features = harlick_features(img_gray, h_neigh, ss_idx)
features = np.hstack((features, h_features))
因为图像分辨率为600x600,特征数目比较多,因此,这里直接从大概 600x600 个像素中随机选择1000点进行训练,而由于计算 Haralick texture features 比较慢,所以对选出来的1000个像素对应的位置才做 Haralick texture features 的计算。
最后得到了1000x13的训练样本的特征矢量。直接调用:
model.fit(X, y)
训练结果展示

参考文档
https://github.com/cerr/CERR/wiki/GLCM_global_features
https://github.com/cerr/CERR/wiki/Haralick-texture-features
20200414