【计算机视觉】图像segmentation and grouping
标签(空格分隔): 【图像处理】
说明:本系列是整理北京理工大学计算机学院硕士课程计算机视觉(英语)的笔记所成,不对之处还望指出。 本章节的主要内容是segmentation and grouping,并讲解几种具体的算法。
##Segmentation and Grouping
mid-level vision的一个关键问题是要找到同时具有compact和expressive的image representations,因为early vision中产生的大量information,所以必须进行summarize。这个summaries可以通过groups of pixels来计算,比如这些像素具有相同的color或者texture等;当然也可以通过计算local pattern elements,比如收集那些看起来在一条线上或者在一个圆形上的edge points。前者就是所谓的segmentation,后者就是所谓的grouping。
###Segmentation
通过focuse on local relations between items的clustering methods,将look similar的clumps of pixels像素块组合在一起。这些像素块通常被叫做regions。
###Grouping
based on global relations,比如all items that lie on a straight line。 suggest the presence of a structure of some form。
###Human Vision: Grouping and Gestalt
人类视觉的一个主要的特征是上下文会影响how things are perceived(感知的),比如Muller-Lyer illusion谬莱尔氏错觉,格式塔学派Gestalt school 强调grouping是理解视觉感知的关键。
Gestalt factors:
proximity:nearby tend to be grouped;
similarity:similar tokens tend to be grouped;
common fate:tokens 具有coherent motion(一致运动)tend to be grouped together;
parallelism:平行的curves或者tokens趋向于grouped together;
symmetry:curves that lead to symmetric groups are grouped together。
##Segmentation
###why to segment?
为何要分隔呢?主要是为了形成一些large chunks of pixels大的像素块来一起处理,for efficiency,它们可能represent objects。
Join up image tokens that together convey information。
###Applications
####Backgroud substraction
通过减去已知的背景,找到interesting bits,比如找到办公室中的person,或者路上的cars。 使用一个moving average来估计背景image,从当前帧减去估计得背景image,绝对值大的是感兴趣的pixels。 trick:使用形态学morphological方法除去多余的像素。
算法步骤:
首先构建一个background estimation $B^{(0)}$,对于每一帧F,更新background estimate,typically by forming
$B^{(n+1)}=\over {w_c}}$
从当前帧减去背景,然后用threshold来提取。
一个比较好的方法是定期更新北京模型,这可以通过计算滑动平均值来实现,即对时序信号计算均值的时候考虑接收到的最新值,如下所示:
$\mu_t = (1-\alpha)\mu_{t-1}+\alpha p_t$
其中,参数$\alpha$表示为学习率,定义了当前值对于平均值的影响程度,该值越大,滑动平均值对观察值适应的速度越快。为了构建背景模型,需要对图像帧的每个像素计算滑动平均数。判断前景要素的依据是当前图像与背景模型之间的差值。
这种方案对于背景相对稳定的简单场景比较有效,然而在许多情况下,背景也许会出现部分区域震荡变化,频繁地检测到错误的前景。这也许是由于运动的背景物体比如落叶或者耀眼的效果水面。提出了更复杂的背景建模方法,比如混合高斯模型,它保存着多个模型,即多个滑动平均值,背景值在两个值之间来回变化,那么将保存两个滑动平均值。如果新的像素值不属于其中之一,那么才会认为它是前景值。另外,不仅保存滑动平均值,还保存滑动方差。计算得到的均值和方差形成一个高斯模型,通过它我们可以获知某个像素属于该模型的概率,它使得确定合适的阈值变得简单,因为现在它表现为一个概率而非差异的绝对值。同时,在背景中变化较明显的区域,前景物体需要的差值将大得多。 最后,当高斯模型的击中频率不高时,它会从当前的模型中移除掉,反之,一个像素位于当前维护的背景模型之外,即认为它是一个前景像素的时候,那么新的高斯模型将会被创建,之后它反复被击中,那么会成为背景的一部分。
####shot boundary detection
镜头边界:两个镜头发生转换的时候,会出现一些明显的变化。例如镜头连续帧之间相应位置像素点差值的变大、颜色分布发生明显的改变或者物体边缘的突然出现与消失。镜头边界是视频镜头相邻帧的内容出现了某种意义上的变化,即镜头边界反映的是视频内容的不连续性。镜头边界检测从本质上讲就是检测这些明显特征的变化
summarize video by find shot boundaries, obtain ”most representative” frame 策略是: 计算帧间距离,声明一个boundary在距离大的地方。
可以用来距离度量的是:
frame differences,histogram differences,block comparisions,edges differences 在一个图像序列中,对每个frame计算其与其前帧的距离,如果距离大于一个阈值,认定这个frame为一个shot boundary
####interactive segmentation 是一种交互式的分割,用户标记出一部分的foreground/background pixels,system cuts objects out of images,对于image editing是有用的。
###superpixels for recognition,for some kinds of reconstruction
replace with superpixels
小的groups of pixels that are clumpy or like one another, a reasonable representation of underlying pixels.
##Image segmentation
给定的图像I,同质性谓词(homogeneity predicate),分割图像到n个regions,满足所有的regions之和是I,每个region内部是相似的,region之间是不相似的。
实际上就是一个将图像中每一个像素都分配一个label,具有相同label的像素具有某种共同的visual characteristics.可以通过gray values来分割,通过texture来分割。
###Segmentation as clustering
有两种类型,一种是agglomerative clustering(merge),一种是divisive clustering(split)。 merge类型是通过将其放入与值最相近/似的cluster中,不断重复;而split类型用最好的边界split cluster,不断重复。 当然还有一个距离的度量pointer-cluster像素点到cluster的距离如何度量呢:
- single-link clustering,指的是像素点到clustering中最近的点那个距离;
- complete-link clustering,指的是像素点到clustering中最远的点的那个距离;
- group-average clustering,指的是像素点到clustering的平均距离。
然后对比一下merging和splitting:
merging呢,首先是将每个point都当作是一个cluster,然后不断地merge the two clusters with the smallest inter-cluster distance.
splitting呢,首先是将整个数据点归为一个cluster,然后不断的split the cluster that yields the two components with largest inter-cluster distance。
所以,两者的区别十分明显。
###merging statically similar regions
算法的主要思想如下:
假设每个region区域内的像素是来自同一个正态分布; 两个毗邻的regions R1和R2各包含m1和m2个points,那么有两种可能的假设hypotheses: H0:两个区域属于同一个object,所以两个region中的像素intensities来自于同一个distribution。 H1:两个区域不属于同一个object,所以来自两个distributions 要进行统计推断,看看到底哪个hypothesis成立: 计算似然函数,实际上也是类条件概率,P(X|y=0),P(X|y=1)
根据似然比来进行统计推断,而里面的参数有三个:$\sigma_0,\sigma_1,\sigma_2$,如何计算呢,实际上就是对region 1和region2 合并后计算估计$\sigma_0$,对region 1计算估计$\sigma_1$,对region 2计算估计$\sigma_2$.还是比较简单的。
###region splitting
如果一个region的某个特性不是一个constant的话,这个region就应该split。 初始化regions in the image; 对每个region,递归的执行如下的步骤:
a) 计算该region内的variance; b) 如果每个region内的variance大于a threshold,用appropriate boundary分割该region。
###watershed algorithm
我的说法就是水漫金山。
它的思想是:将image看作是3D,空间坐标和gray levels,意思就是用高度来表示像素intensity。 这是一种地形上的解释,这样的话image中的像素点可分为三种:一种是属于regional minimum的points;一种是处于一个山腰上的points,它将fall into a single minimum;一种是处于峰顶的,它将等概率的fall into more than one minimum,将构成divide lines or watershed lines。使用watershed algorithm就是为了找到第三种点的集合。
想象一下,在各个region的local minimum处开一个小洞,让水漫进来,逐渐淹没,标记住连接两个或以上region的像素点,由它们构成所谓的watershed lines。而不同的盆地将不断地被merge,一个水坝被建立来组织merging,这个水坝就是相应的watershed lines。
来看看watershed algorithm是如何实现的: 用最小的可能的value来开始,构成最初的initial watersheds。
For each intensity level k:
For each group of pixels of intensity k
If adjacent to exactly one existing region, add
these pixels to that region
Else if adjacent to more than one existing
regions, mark as boundary
Else start a new region
在像素的8邻域内检测,看看有没有相邻的regions,如果没有的话,则新建region,有的话,如果只有一个,那么加入到这个region中,如果有两个或者以上,则mark为boundary。
很简单了,先从最低的像素值开始,刚开始一个region都没有,然后遍历所有处于该value的像素点,按照上面的标准去分配区域,然后提高value值,继续判断。最后就能得到对应的watershed lines。
但是有一个问题是:如下: 1 1 1 1 3 3 3 3,在分配区域的时候,第一轮,设置灰度值为1,那么前四个1归为一个region,然后进行第二轮,设置灰度值为3,那么剩下的4个3逐步的判断,都有一个region与之相邻,那么归为该region,最后只得到一个region,所以问题来了,对于不同的像素值,居然分到了同一个region中,很明显应当从1,3之间分开的嘛! 那么一种解决的方法就是取梯度图:用算子 -1 1来计算梯度: 0 0 0 2 0 0 0 那么在分配区域的时候,前三个0分为一个region1 ,后三个0分为一个region 2,而在判断2的时候,就会发现它实际上是有两个region与之相邻,那么它就是所谓的watershed lines上的point。
这就是在梯度图上做watershed algorithm。
还有,如果有噪声或者其他梯度局部不规则的话,会出现过度分割的现象,太多的region了。 一种解决办法是限制区域最小值的数量,使用markers来指定允许的regional minimal,就是说水从指定的regional minimal上开始往上漫进来。
###cluster pixels
使用K-means,represent pixels用intensity vector,color vector,vector of nearby filter responses等,perhaps position。
使用K-means要注意Axis scaling,不同的features可能具有不同的scales,问题是features with larger scales dominate clustering,解决办法就是scale the features。 K值选的不同当然也就不同。所以K是提前给出的。
###mean shift algorithm
meanshift也比较简单,逐渐去寻找mass的重心,也是一个交替优化的过程,首先随机选取一个位置,找到以该位置为半径的圆的重心,然后将位置指向该重心,得到的就是meanshift vector,然后该位置加上这个vector就可以转移到这里,然后再以该位置为中心,相同半径下圆的重心,逐步迭代进行。直到meanshift vector很小为止。计算中心的时候不一定使用均值,可以使用kernel function来进行平滑,比如一个非常合理的假设就是距离越近的权重应该越高,所以Gaussian Kernel应该是一个不错的选择,于是meanshift就变味了kernel meanshift,KMS。
Until the update is tiny
form the new estimate
n data vectors $x_i$ of dimension d,g is the kernel function,a scaling constant h。
实际上是用meanshift只是为了找到mode的peak位置。 对每个像素都使用meanshift可能得到很多个mode,之后要进行clustering the mode,然后遍历每一个pixels,选择最近的mode,分配labels。
大概就是这样了。meanshift的原理很简单,尤其是以迭代优化为alternative optimization,先优化重心,然后再优化区域。如果是两个变量的话,类似于coordinate ascent。坐标上升。
####clustering with Meanshift
对于每个数据点$x_i$,使用meanshift procedure,以$y^{(0)}=x_i$开始,记录结果的模式为$y_i$; 对$y_i$进行cluster,形成一个小的紧凑的clusters; 一个好的选择是merge clusters with group average distance,直到group distance 超过一个小的阈值为止。
####Mean Shift Segmentation
当然在图像分割中,使用meanshift方法,有如下步骤:
对于每一个像素,计算它的特征矢量$x_i=(x_i^s,x_i^r)$表示它的spatial and appearance components; 选择smoothing kernel function的尺度系数:$h_s,h_r$; 使用meanshift clustering,得到一系列的mode,或者初步的clusters; merge clusters with fewer than $t_min$ pixels with a neighbor;选择neighbor is not significant,因为cluster是tiny的。
【增补】
####Graph-based clustering 基于图论的clustering,将image看作是一个graph,一张weighted graph,带有权重的graph,这个权重是对应像素间的相似性,大的weight代表similar,小的weight代表different,也就是说,这个node之间的权重对应的是两个node 像素间的相似性,那么分割的时候的边界对应的是像素最不相似的地方,那么对应的权重也应该是最小。这个权重通常通过position,color和texture vectors来计算得到,典型的计算公式如下:
距离distance,相似度越大,距离越小,对应的权重计算也越大;反之,距离distance大,相似度越小,对应的权重计算也就越小。
Graph-based clustering的算法如下:
- 开始时将每个像素设置为一个cluster;
- 将edges按照edges 权重单调不减进行排序,即$w(e_1)\ge w(e_2)\ge w(e_3)\ge …\ge w(e_r)$
- 对这些edges进行遍历,对于每个edges,判断edges是否在一个cluster内部,如果是则跳过,如果不是,那么一端在cluster $C_l$,另一端在cluster $C_m$,计算两个cluster的$diff(C_l,C_m)$,如果小于某一个值的话,将两个cluster进行merge。
- 输出剩余的clusters 这个set就是最后的clusters。 这种方法实际上是一种基于merge的clustering方法,但是它利用的graph,图论。注意:这里面所说的edges,指的不是经过梯度处理提取的edges,而是指两个node之间的edges,这个edge上的权重就是前面所讲的那个权重,衡量的是两个nodes之间相似性,相似性越大,weights也越大,说明更可能是同一类。所以,上面将weights按照从大到小的顺序排列,也是出于这个道理,先将更加相似的node输入到里面,开始的时候肯定是大范围的merge,merge的效果更加好,使得算法一开始就能将大量相似性的node给merge,剩下的cluster可能就少了,能够加速clustering的速度。
####Graph-based segmentation 首先是将represent image by graph,每个像素都是一个node,那么edges of graph表示的就是像素之间的相似度,图像的分割,就对应于graph的partition。想想分割图的时候,就是找到图像链接权重最小的区域,一刀切下去,就把graph切成两半了。大概就是这样的思路吧。
Min cut算法,给定一个graph,G(V,E,W),V表示它的nodes,E表示它的edges,就是无方向的边,而W对应着weights矩阵。a cut on a graph,就是将V分割为两个子集A和B,A,B之间不交叠,AUB=V。min cut的思想呢就是链接A和B的这个edges的权重之和应该是最小的。这就是min cut的叫法的来源。
这个公式很好理解,就是A中的nodes与B中的nodes的所有有链接的边的权重之和。找一个最小的出来,作为cut的依据。
normalized cuts,就是用A和V中的cut,B和V中的cut,V指的是all nodes,进行normalization,公式如下:
assoc(A,V)实际上就是A中nodes与V中nodes的所有边界权重之和。
关于Graph weight matrix W,它实际上是一个对称方阵,大小为$(w\times h)\times (w\times h)$,每一行i或者每一列j都是一张$(w\times h)$的image。表示的是image中所有像素与image中第i个或者第j个像素的相似度图。
##评估一下分割的性能
当然要先有groundtruth才能量化评估,那么收集正确分割的方法可以是人工标定,这种方法虽然不一定完美,但是几乎是最好的了。目前机器没有人做得好。
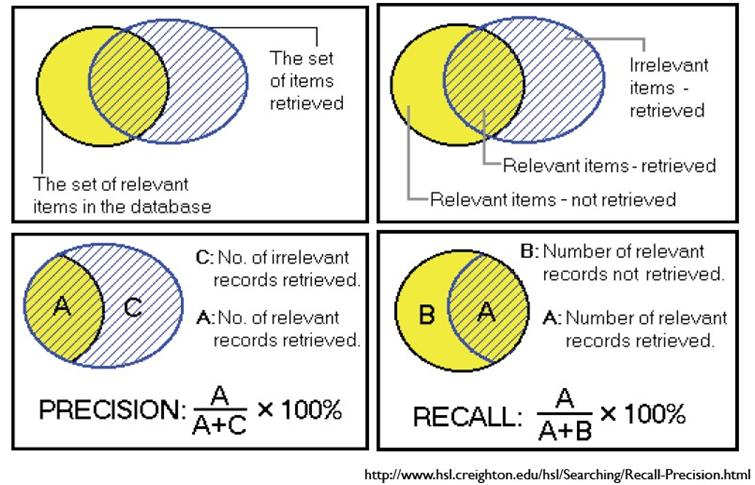
这里有两个指标一个是recall,一个是precision: Precision (P) is defined as the number of true positives ($T_p$) over the number of true positives plus the number of false positives ($F_p$).
Recall (R) is defined as the number of true positives ($T_p$) over the number of true positives plus the number of false negatives ($F_n$).
在这里recall指的是所有是human boundary pixels中被找出来是boundary的像素占其中的比例,而precision指的是所有是human boundary pixels中被找出来是boundary的像素占我找出来的boundary像素中的比例。
我们当然希望结果P越高越好,R也越高越好,但事实上这两者在某些情况下是矛盾的。比如极端情况下,我们只找出了一个像素,这个像素是属于boundaries的,是准确的,那么P就是100%,但是R就很低;而如果我们把所有结果都返回,那么必然R是100%,但是P很低。